Elasticsearch 系列文章——分词(IK)
发布时间:2018-01-10 16:31:07编辑:丝画阁阅读(1335)
Elasticsearch 系列文章
Elasticsearch 系列文章——分词(IK)
Elasticsearch 系列文章——分词(pinyin)
Elasticsearch 系列文章——分词、全文检索(Java)
Elasticsearch 系列文章——分词器原理解析
Elasticsearch 系列文章——kibana 使用详解
欢迎Elasticsearch技术爱好者 互相关注,技术交流
本文目录:
分词器的作用
分词器安装(IK)
测试案例
注:本文范例版本:Elasticsearch-5.2.2
分词器的作用
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词。例如:
“我是中国人” 会分解成:“ 我”“是”“中”“国”“人”。
正常情况下,这不是我们想要的结果,比如我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要安装中文分词插件。
常见的分词算法就是拿一个标准的词典,关键词都在这个词典里面。然后按照几种规则去查找有没有关键词,比如:
-
正向最大匹配(从左到右)
-
逆向最大匹配(从右到左)
-
最少切分
-
双向匹配(从左扫描一次,从右扫描一次)
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库。
该分词器分为两种分词方法:ik_max_word 和 ik_smart
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
分词器安装
安装elasticsearch-analysis-ik
1、下载,编译IK文件
git clone https://github.com/medcl/elasticsearch-analysis-ikcd elasticsearch-analysis-ik
git checkout tags/v5.2.2
mvn clean
mvn compile
mvn package
2、将编译生成的文件拷贝到elasticsearch相应的目录copy and unzip target/releases/elasticsearch-analysis-ik-{version}.jar
to your-es-root/plugins/ik
3、重启elasticsearch
测试案例—DSL

(用户Kibana 快速创建,后续构建代码全部使用该工具执行)
1、创建索引:index
PUT index
{
}
2、创建type和属性
POST index/type/_mapping
{
"type": {
"_all": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"term_vector": "no",
"store": "false"
},
"properties": {
"test1": {
"type": "string",
"store": "no",
"analyzer": "whitespace",
"include_in_all": "true"
},
"test2": {
"type": "string",
"store": "no",
"index": "not_analyzed",
"include_in_all": "true"
},
"test3": {
"type": "string",
"store": "no",
"include_in_all": "true"
},
"test4": {
"type": "string",
"store": "no",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"include_in_all": "true"
}}}}
上面的命令,是定义index索引下type类型的映射。其中定义了_all字段的分析方法,以及test1、test2、test3、test4、属性的分析方法。
这里介绍下什么是_all字段,其实_all字段是为了在不知道搜索哪个字段时,使用的。es会把所有的字段(除非你手动设置成false),都放在_all中,然后通过分词器去解析。当你使用query_string的时候,默认就在这个_all字段上去做查询,而不需要挨个字段遍历,节省了时间。
properties中定义了特定字段的分析方式。在上面的例子中,仅仅设置了content的分析方法。
-
type,字段的类型为string,只有string类型才涉及到分词,像是数字之类的是不需要分词的。
-
store,定义字段的存储方式,no代表不单独存储,查询的时候会从_source中解析。当你频繁的针对某个字段查询时,可以考虑设置成true。
-
term_vector,定义了词的存储方式,with_position_offsets,意思是存储词语的偏移位置,在结果高亮的时候有用。
-
analyzer,定义了索引时的分词方法
-
search_analyzer,定义了搜索时的分词方法
-
include_in_all,定义了是否包含在_all字段中
其中:
test1:"analyzer": "whitespace" :空格分词
test2:"index": "not_analyzed" :不分词
test3:默认分词
test4:"analyzer": "ik_max_word" :设置IK分词
3、插入数据
POST index/type/1
{
"test1":"中国开通第一个5G基站,China opened the first 5g base station",
"test2":"中国开通第一个5G基站,China opened the first 5g base station",
"test3":"中国开通第一个5G基站,China opened the first 5g base station",
"test4":"中国开通第一个5G基站,China opened the first 5g base station"
}
4、查看数据
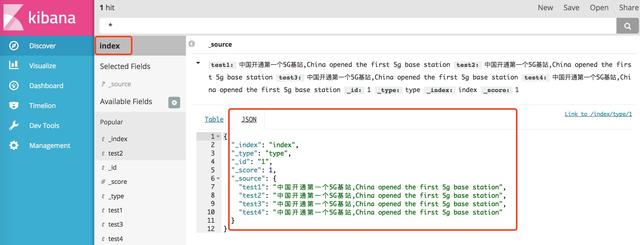
5、查看分词情况

(截图来自Kibana)
其中:
"test1": [
"@kibana-highlighted-field@中国开通第一个5G基站,China@/kibana-highlighted-field@ @kibana-highlighted-field@opened@/kibana-highlighted-field@ @kibana-highlighted-field@the@/kibana-highlighted-field@ @kibana-highlighted-field@first@/kibana-highlighted-field@ @kibana-highlighted-field@5g@/kibana-highlighted-field@ @kibana-highlighted-field@base@/kibana-highlighted-field@ @kibana-highlighted-field@station@/kibana-highlighted-field@"
]
"test2": [
"@kibana-highlighted-field@中国开通第一个5G基站,China opened the first 5g base station@/kibana-highlighted-field@"
]
"test3": [
"@kibana-highlighted-field@中@/kibana-highlighted-field@@kibana-highlighted-field@国@/kibana-highlighted-field@@kibana-highlighted-field@开@/kibana-highlighted-field@@kibana-highlighted-field@通@/kibana-highlighted-field@@kibana-highlighted-field@第@/kibana-highlighted-field@@kibana-highlighted-field@一@/kibana-highlighted-field@@kibana-highlighted-field@个@/kibana-highlighted-field@@kibana-highlighted-field@5G@/kibana-highlighted-field@@kibana-highlighted-field@基@/kibana-highlighted-field@@kibana-highlighted-field@站@/kibana-highlighted-field@,@kibana-highlighted-field@China@/kibana-highlighted-field@ @kibana-highlighted-field@opened@/kibana-highlighted-field@ @kibana-highlighted-field@the@/kibana-highlighted-field@ @kibana-highlighted-field@first@/kibana-highlighted-field@ @kibana-highlighted-field@5g@/kibana-highlighted-field@ @kibana-highlighted-field@base@/kibana-highlighted-field@ @kibana-highlighted-field@station@/kibana-highlighted-field@"
]
"test4": [
"@kibana-highlighted-field@中国@/kibana-highlighted-field@@kibana-highlighted-field@开通@/kibana-highlighted-field@@kibana-highlighted-field@第一个@/kibana-highlighted-field@@kibana-highlighted-field@5G@/kibana-highlighted-field@@kibana-highlighted-field@基站@/kibana-highlighted-field@,@kibana-highlighted-field@China@/kibana-highlighted-field@ @kibana-highlighted-field@opened@/kibana-highlighted-field@ the @kibana-highlighted-field@first@/kibana-highlighted-field@ @kibana-highlighted-field@5g@/kibana-highlighted-field@ @kibana-highlighted-field@base@/kibana-highlighted-field@ @kibana-highlighted-field@station@/kibana-highlighted-field@"
]
6、分词查询:
三种方式查询:term,match,query_string
term:精准查询,直接使用关键字进行查询,不对关键字进行分词
match匹配的时候,会将查询的关键字进行分词,然后根据分词后的结果进行查询
1、match:
GET index/_search
{
"query" : { "match" : { "test4" : "中国开通第一个" }},
"highlight" : {
"pre_tags" : ["
"post_tags" : ["
"],
"fields" : {
"test4" : {}
}}}
2、term
GET index/_search
{
"query" : { "term" : { "test4" : "中国" }},
"highlight" : {
"pre_tags" : ["
"post_tags" : ["
"],
"fields" : {
"test4" : {}
}}}
3、query_string
GET index/_search
{
"query":{
"query_string": {
"default_field": "test4",
"query":"中国开通第一个"
}},
"highlight" : {
"pre_tags" : ["
"post_tags" : ["
"],
"fields" : {
"test4" : {}
}
}
}
查询结果:
"highlight": {
"test4": [
"开通第一个5G基站,China opened the first 5g base station"
]
}
预告:下一篇文章(Elasticsearch 系列文章——分词pinyin)
简介:
pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。
比如,输入
shuihu
就能匹配到
水壶
输入
刘德h,刘dh,ldh,dh
就能匹配到
刘德华
关键字: