数据分析师需要掌握的10个统计方法(下)
发布时间:2018-04-29 22:23:42编辑:丝画阁阅读(1193)

在上篇文章中,我们介绍了线性回归、分类、重采样方法、子集选择、特征缩减技术5种统计方法。接下来我们继续介绍其他的5种。
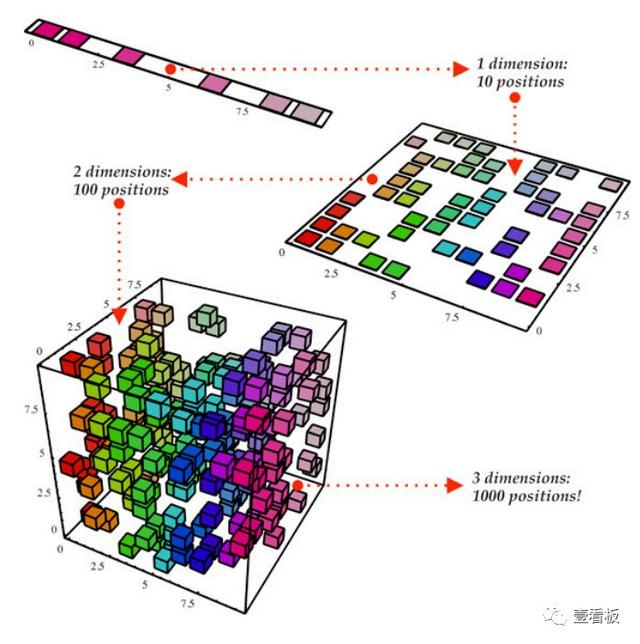
6、维数缩减(DimensionReduction)
维数缩减将估计p + 1个系数的问题简化为M +1个系数的简单问题,其中M
-
可以将主成分回归描述为从大量变量中导出低维特征集合的方法。数据的第一主成分方向是观测值变化最大的。换句话说,第一台PC是尽可能接近数据的一条线。人们可以适应不同的主要组成部分。第二个PC是与第一个PC不相关的变量的线性组合,并且受这个约束的变化最大。这个想法是,主要组件在随后的正交方向上使用数据的线性组合捕获数据中最大的方差。通过这种方式,我们也可以结合相关变量的效果,从可用数据中获取更多信息,而在正则最小二乘中,我们将不得不放弃其中一个相关变量。
-
我们上面描述的PCR方法包括确定最能代表预测因子的X的线性组合。这些组合(方向)以无监督的方式被识别,因为响应Y不用于帮助确定主要组件方向。也就是说,响应Y不监督主成分的识别,因此不能保证最能解释预测因子的方向对于预测响应(即使经常假设)也是最好的。偏最小二乘法(PLS)是PCR的监督替代方法。与PCR一样,PLS是一种降维方法,它首先识别一组新的较小的特征,这些特征是原始特征的线性组合,然后通过最小二乘法拟合一个线性模型到新的M特征。然而,与PCR不同的是,PLS利用响应变量来识别新的特征。
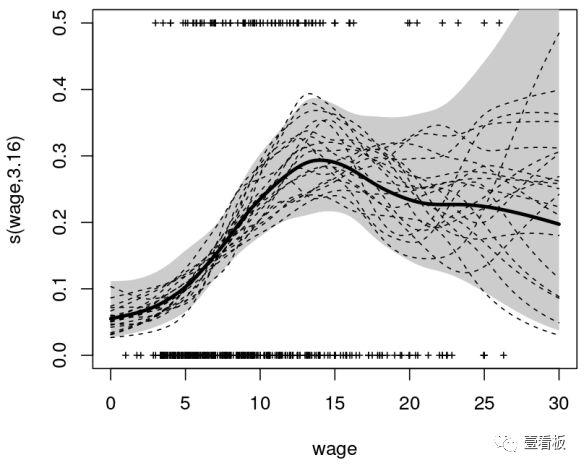
7、非线性模型(NonlinearModels)
在统计学中,非线性回归是回归分析的一种形式,其中观测数据是由一个函数建模的,该函数是模型参数的非线性组合,并取决于一个或多个自变量。数据通过逐次逼近的方法进行拟合。以下是一些处理非线性模型的重要技巧:
-
一个实数函数被称为阶段函数(或者阶梯函数),则它可以被写作:有限的间隔指标函数的线性组合。不正规的说法是,一个阶段函数就是一个分段常值函数,只是含有的阶段很多但是有限。
-
分段函数是对于自变量x的不同的取值范围,有着不同的对应法则,这样的函数通常叫做分段函数。它是一个函数,而不是几个函数。分段函数的定义域是各段函数定义域的并集,值域也是各段函数值域的并集。例如,分段多项式函数是在其每个子域上是多项式的函数,但是每个子域上可能是不同的。
-
样条函数是由多项式分段定义的特殊函数。在计算机图形学中,样条是指分段多项式参数曲线。由于其结构简单,评估方便和准确,以及通过曲线拟合和交互式曲线设计逼近复杂形状的能力,样条曲线非常流行。
-
广义加性模型是线性预测器线性依赖于某些预测变量的未知光滑函数的广义线性模型,侧重于这些光滑函数的推理。
8、基于树的方法(Tree-BasedMethods)
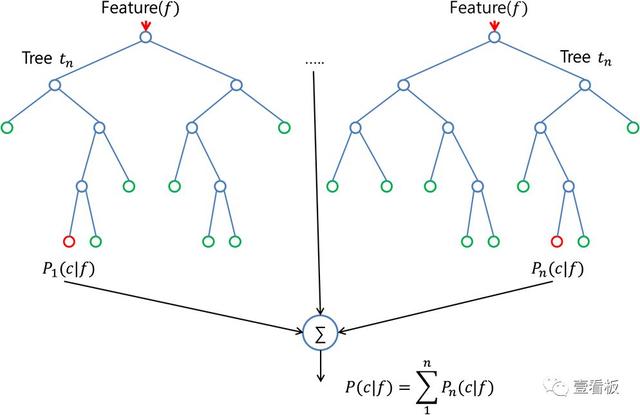
基于树的方法可以用于回归和分类问题。这些涉及将预测空间分层或分割成若干简单区域。由于用于分割预测变量空间的分裂规则集合可以在树中进行概括,所以这些类型的方法被称为决策树方法。下面的方法生成多个树,然后结合在一起产生一个单一的共识预测。
-
套袋(Bagging)是减少预测方差的方法,通过使用重复组合来生成原始数据集中的训练数据,从而生成与原始数据相同的多样性。通过增加你的训练集的大小,你不能提高模型的预测力,但只是减少方差,狭义地调整预测到预期的结果。
-
提升(Boosting)是一种使用几种不同的模型计算产出的方法,然后使用加权平均方法对结果进行平均。通过改变你的加权公式,结合这些方法的优点和缺陷,你可以使用不同的狭义调整模型,为更广泛的输入数据提供一个很好的预测力。
-
随机森林算法(randomforest)是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
9、支持向量机(Support VectorMachines)
SVM是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。通俗地说,它包括找到超平面(2D中的线,3D中的平面和更高维中的超平面),更正式地说,超平面是n维空间中的n维空间)最大保证金从本质上讲,它是一个约束优化问题,其边界被最大化,受限于它对数据进行了完美的分类(硬边缘)。
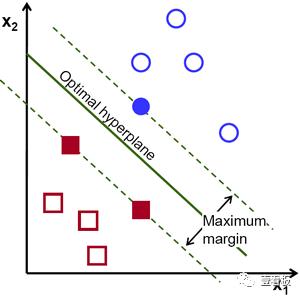
这种“支持”这个超平面的数据点被称为“支持向量”。在上图中,填充的蓝色圆圈和两个实心方块是支持向量。对于两类数据不能线性分离的情况,这些点被投影到可能线性分离的分解(高维)空间。涉及多个类的问题可以分解为多个一对一或者一对二的分类问题。
10、无监督学习(UnsupervisedLearning)
到目前为止,我们只讨论了监督学习技术,其中组是已知的,提供给算法的经验是实际实体和它们所属的组之间的关系。当数据的组(类别)未知时,可以使用另一组技术。它们被称为无监督的,因为它留在学习算法中以找出所提供的数据中的模式。聚类是无监督学习的一个例子,其中不同的数据集被聚类为密切相关的项目组。下面是最广泛使用的无监督学习算法的列表:
-
主成分分析通过识别一组具有最大方差和相互不相关的特征的线性组合来帮助产生数据集的低维表示。这种线性维度技术有助于理解变量在无监督环境下的潜在相互作用。
-
k-Means聚类:根据到群集质心的距离将数据分为k个不同的聚类。
-
分层集群:通过创建集群树来构建集群的多级分层结构。
以上10种方法是基本的统计方法,可以帮助数据科学项目的管理人员更好地理解他们的团队底层正在运行的是什么。实际上,一些数据科学小组纯粹通过python和R运行算法。他们中的大多数甚至不必考虑潜在的数学问题。
但是,能够理解统计分析的基础知识可以为您的团队提供更好的方法。深入了解最底层的原理可以更轻松地进行操作和抽象。希望这个基础的数据科学统计指南给您带来更深层次的理解!
关键字: