MYSQL 全套资料
发布时间:2018-11-17 11:51:48编辑:丝画阁阅读(1048)
MySQL简介
1、什么是数据库 ?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。数据库有很多种类型,从最简单的存储有各种数据的表格到能够进行海量数据存储的大型数据库系统都在各个方面得到了广泛的应用。
主流的数据库有:sqlserver,mysql,Oracle、SQLite、Access、MS SQL Server等,本文主要讲述的是mysql
2、数据库管理是干什么用的?
- a. 将数据保存到文件或内存
- b. 接收特定的命令,然后对文件进行相应的操作
PS:如果有了以上管理系统,无须自己再去创建文件和文件夹,而是直接传递 命令 给上述软件,让其来进行文件操作,他们统称为数据库管理系统(DBMS,Database Management System)
MySQL安装
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),MySQL数据库系统使用最常用的数据库管理语言–结构化查询语言(SQL)进行数据库管理。在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
使用mysql必须具备一下条件
- a. 安装MySQL服务端
- b. 安装MySQL客户端
- c. 【客户端】连接【服务端】
- d. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
1、下载地址:http://dev.mysql.com/downloads/mysql/
2、安装
- windows安装请参考:http://www.cnblogs.com/lonelywolfmoutain/p/4547115.html
- linux下安装:http://www.cnblogs.com/chenjunbiao/archive/2011/01/24/1940256.html
注:以上两个链接有完整的安装方式,撸主也是参考他的安装的,安装完以后mysql.server start启动mysql服务
MySQL操作
一、连接数据库
mysql -u user -p 例:mysql -u root -p
常见错误如下:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2), it means that the MySQL server daemon (Unix) or service (Windows) is not running.
退出连接:
QUIT 或者 Ctrl+D
二、查看数据库,创建数据库,使用数据库查看数据库:
show databases;
默认数据库:
mysql - 用户权限相关数据 test - 用于用户测试数据 information_schema - MySQL本身架构相关数据
创建数据库:
create database db1 DEFAULT CHARSET utf8 COLLATE utf8_general_ci; # utf8编码 create database db1 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci; # gbk编码
使用数据库:
use db1;
显示当前使用的数据库中所有表:
SHOW TABLES;
三、用户管理
创建用户
create user '用户名'@'IP地址' identified by '密码';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';
修改密码
set password for '用户名'@'IP地址' = Password('新密码');
注:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
四、权限管理
mysql对于权限这块有以下限制:
all privileges:除grant外的所有权限 select:仅查权限 select,insert:查和插入权限 ... usage:无访问权限 alter:使用alter table alter routine:使用alter procedure和drop procedure create:使用create table create routine:使用create procedure create temporary tables:使用create temporary tables create user:使用create user、drop user、rename user和revoke all privileges create view:使用create view delete:使用delete drop:使用drop table execute:使用call和存储过程 file:使用select into outfile 和 load data infile grant option:使用grant 和 revoke index:使用index insert:使用insert lock tables:使用lock table process:使用show full processlist select:使用select show databases:使用show databases show view:使用show view update:使用update reload:使用flush shutdown:使用mysqladmin shutdown(关闭MySQL) super:使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆 replication client:服务器位置的访问 replication slave:由复制从属使用
对于数据库及内部其他权限如下:
数据库名.* 数据库中的所有 数据库名.表 指定数据库中的某张表 数据库名.存储过程 指定数据库中的存储过程 *.* 所有数据库
对于用户和IP的权限如下:
用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)
1、查看权限:
show grants for '用户'@'IP地址'
2、授权
grant 权限 on 数据库.表 to '用户'@'IP地址'
3、取消授权
revoke 权限 on 数据库.表 from '用户名'@'IP地址'
授权实例如下:
grant all privileges on db1.tb1 TO '用户名'@'IP' grant select on db1.* TO '用户名'@'IP' grant select,insert on *.* TO '用户名'@'IP' revoke select on db1.tb1 from '用户名'@'IP'
MySQL表操作
1、查看表
show tables; # 查看数据库全部表 select * from 表名; # 查看表所有内容
2、创建表
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGINE=InnoDB DEFAULT CHARSET=utf8
来一个实例好详解
CREATE TABLE `tab1` ( `nid` int(11) NOT NULL auto_increment, `name` varchar(255) DEFAULT zhangyanlin, `email` varchar(255), PRIMARY KEY (`nid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
注:
- 默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
- 自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列)注意:1、对于自增列,必须是索引(含主键)2、对于自增可以设置步长和起始值
- 主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
3、删除表
drop table 表名
4、清空表内容
delete from 表名 truncate table 表名
5、修改表
添加列: alter table 表名 add 列名 类型 删除列: alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键: alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键: alter table 表名 drop foreign key 外键名称 修改默认值: ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; 删除默认值: ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
对于上述这些操作是不是看起来很麻烦,很浪费时间,别慌!有专门的软件能提供这些功能,操作起来非常简单,这个软件名字叫Navicat Premium ,大家自行在网上下载,练练手,但是下面的即将讲到表内容操作还是建议自己写命令来进行
6、基本数据类型
MySQL的数据类型大致分为:数值、时间和字符串
bit[(M)]
二进制位(101001),m表示二进制位的长度(1-64),默认m=1
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127.
无符号:
0 ~ 255
特别的: MySQL中无布尔值,使用tinyint(1)构造。
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
0 ~ 4294967295
特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为:00002
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615
decimal[(m[,d])] [unsigned] [zerofill]
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
特别的:对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-3.402823466E+38 to -1.175494351E-38,
0
1.175494351E-38 to 3.402823466E+38
有符号:
0
1.175494351E-38 to 3.402823466E+38
**** 数值越大,越不准确 ****
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
0
2.2250738585072014E-308 to 1.7976931348623157E+308
有符号:
0
2.2250738585072014E-308 to 1.7976931348623157E+308
**** 数值越大,越不准确 ****
char (m)
char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。
PS: 即使数据小于m长度,也会占用m长度
varchar(m)
varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext
A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
enum
枚举类型,
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
set
集合类型
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS('-838:59:59'/'838:59:59')
YEAR
YYYY(1901/2155)
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
MySQL表内容操作
表内容操作无非就是增删改查,当然用的最多的还是查,而且查这一块东西最多,用起来最难,当然对于大神来说那就是so easy了,对于我这种小白还是非常难以灵活运用的,下面咱来一一操作一下
1、增
insert into 表 (列名,列名...) values (值,值,...)
insert into 表 (列名,列名...) values (值,值,...),(值,值,值...)
insert into 表 (列名,列名...) select (列名,列名...) from 表
例:
insert into tab1(name,email) values('zhangyanlin','zhangyanlin8851@163.com')
2、删
delete from 表 # 删除表里全部数据 delete from 表 where id=1 and name='zhangyanlin' # 删除ID =1 和name='zhangyanlin' 那一行数据
3、改
update 表 set name = 'zhangyanlin' where id>1
4、查
select * from 表 select * from 表 where id > 1 select nid,name,gender as gg from 表 where id > 1
查这块的条件太多太多我给列举出来至于组合还得看大家的理解程度哈
a、条件判断where
select * from 表 where id > 1 and name != 'aylin' and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表)
b、通配符like
select * from 表 where name like 'zhang%' # zhang开头的所有(多个字符串) select * from 表 where name like 'zhang_' # zhang开头的所有(一个字符)
c、限制limit
select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行
d、排序asc,desc
select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
e、分组group by
select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前
《MySQL入门全套》讲的是MySQL的基本操作,禁不住大家的热情,所以进阶来了。这一篇讲的是进阶,会有一点难以理解,本节主要内容MySQL视图,存储过程,函数,事务,触发器,以及动态执行SQL。
视图view
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。视图是存储在数据库中的查询的SQL 语句,它主要出于两种原因:安全原因, 视图可以隐藏一些数据。
1、创建视图
--格式:CREATE VIEW 视图名称 AS SQL语句 CREATE VIEW v1 AS SELET nid, name FROM tab1 WHERE nid > 4
2、删除视图
--格式:DROP VIEW 视图名称 DROP VIEW v1
3、修改视图
-- 格式:ALTER VIEW 视图名称 AS SQL语句 ALTER VIEW v1 AS SELET A.nid,B. NAME FROM tab1 LEFT JOIN B ON A.id = B.nid LEFT JOIN C ON A.id = C.nid WHERE tab1.id > 2
也就只是改了把create改成alter,中间的语句更换了。
4、使用视图
使用视图时,将其当作表进行操作即可,由于视图是虚拟表,所以无法使用其对真实表进行创建、更新和删除操作,仅能做查询用。
select * from v1
存储过程procedure
1、我们为什么要用存储过程呢 ?
我们都知道应用程序分为两种,一种是基于web,一种是基于桌面,他们都和数据库进行交互来完成数据的存取工作。假设现在有一种应用程序包含了这两 种,现在要修改其中的一个查询sql语句,那么我们可能要同时修改他们中对应的查询sql语句,当我们的应用程序很庞大很复杂的时候问题就出现这,不易维 护!另外把sql查询语句放在我们的web程序或桌面中很容易遭到sql注入的破坏。而存储例程正好可以帮我们解决这些问题。
2、创建存储过程
创建存储过程这块主要有两种,一种是带参数的,一种是不带参数的,先讲不带参数的再说不带参数的。
不带参数案例:
-- 创建存储过程 delimiter // --自定义语句结尾符号,因为这里要执行好多句sql语句,所以就得自定义,以防止出错 create procedure p1() BEGIN select * from tab1; END// delimiter ; --自定义局域结尾符号结束 -- 执行存储过程 call p1()
带参数案例这块主要有三个类
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
-- 创建存储过程 delimiter \ create procedure p1( in i1 int, -- 传入参数i1 in i2 int, -- 传入参数i2 inout i3 int, -- 即传入又能得到返回值 out r1 int -- 得到返回值 ) BEGIN DECLARE temp1 int; DECLARE temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end\ delimiter ; -- 执行存储过程 DECLARE @t1 INT default 3; -- 设置变量默认值为3 DECLARE @t2 INT; -- 设置变量 CALL p1 (1, 2 ,@t1, @t2); -- 执行存储过程,并传入参数,t2自动取消 SELECT @t1,@t2; -- 查看存储过程输出结果
3、删除存储过程
drop procedure p1;
4、Python用pymysql模块调用存储过程,因为我们学习这些就是为了语言调用
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='day39b_')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 执行存储过程
row = cursor.callproc('p1',(1,2,3))
# 存储过程的查询结果
selc = cursor.fetchall()
print(selc)
# 获取存储过程返回
effect_row = cursor.execute('select @_p1_0,@_p1_1,@_p1_2')
# 曲存储过程的返回值
ret = cursor.fetchone()
print(ret)
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
函数function
在MySQL中有很多内置函数,比如我们经常用的求平均值,求和,个数,各式各样,先给大家来一部门内置函数,然后再说说自定义函数吧,函数也可以传参数,也可以接收返回值,但是函数没办法得到执行语句得到的结果,存储过程可以。
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。
CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示
FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。
LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。
LOWER(str)
变小写
UPPER(str)
变大写
LTRIM(str)
返回字符串 str ,其引导空格字符被删除。
RTRIM(str)
返回字符串 str ,结尾空格字符被删去。
SUBSTRING(str,pos,len)
获取字符串子序列
LOCATE(substr,str,pos)
获取子序列索引位置
REPEAT(str,count)
返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。
若 count 若str 或 count 为 NULL,则返回 NULL 。
REPLACE(str,from_str,to_str)
返回字符串str 以及所有被字符串to_str替代的字符串from_str 。
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
RIGHT(str,len)
从字符串str 开始,返回从后边开始len个字符组成的子序列
SPACE(N)
返回一个由N空格组成的字符串。
SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str)
返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
mysql> SELECT TRIM(' bar ');
-> 'bar'
mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx'
mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar'
mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx'
更多参考请参考中文文档【http://doc.mysql.cn/mysql5/refman-5.1-zh.html-chapter/functions.html#encryption-functions】
1、自定义创建函数
delimiter \ create function f1( i1 int, i2 int) returns int BEGIN declare num int; set num = i1 + i2; return(num); END \ delimiter ;
2、删除函数
drop function f1;
3、执行函数
# 获取返回值
declare @i VARCHAR(32);
select UPPER('alex') into @i;
SELECT @i;
# 在查询中使用
select f1(11,nid) ,name from tb2;
事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。例如:当两张银行卡之间进行转账,甲方钱转出去了,突然光缆坏了,乙方还没收到钱,钱跑哪里去了,就为了防止这种情况,事务就出来了,事务可以防止这种事情发生。
应用事务实例:
delimiter \
create PROCEDURE p1(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;
START TRANSACTION;
DELETE from tb1; -- sql语句都放在这个里面
insert into tb2(name)values('seven');
COMMIT;
-- SUCCESS
set p_return_code = 0;
END\
delimiter ;
执行存储过程:
DECLARE @i TINYINT; call p1(@i); select @i;
触发器TRIGGER
触发器,简单来说就是当你在执行这条语句之前或者之后触发一次增删改查,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
1、基本语法
# 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入后 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 删除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 删除后 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新后 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END
示例一插入前:
-- 在往tab1插入数据之前往tab2中插入一条name = 张岩林,当然是在判断往tab1中插入的名字是不是等于aylin
delimiter //
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
IF NEW. NAME == 'aylin' THEN
INSERT INTO tb2 (NAME)
VALUES
('张岩林')
END
END//
delimiter ;
示例二插入后:
delimiter //
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
IF NEW. num = 666 THEN
INSERT INTO tb2 (NAME)
VALUES
('张岩林'),
('很帅') ;
ELSEIF NEW. num = 555 THEN
INSERT INTO tb2 (NAME)
VALUES
('aylin'),
('非常帅') ;
END IF;
END//
delimiter ;
同样的删,改,查都是同样的道理。
特别的:NEW表示即将插入的数据行,OLD表示即将删除的数据行。
2、删除触发器
DROP TRIGGER tri_after_insert_tb1;
3、使用触发器
触发器无法由用户直接调用,而知由于对表的【增/删/改】操作被动引发的。
insert into tb1(name) values(‘张岩林’)
最近做的项目与数据库关系密切,自然少不了很多SQL。下面总结一下最近使用的能够较大提升工作效率的SQL。
1、根据表2的某个字段来更新表1的某个字段
这是一个坑,错误的写法是
update table_name_1 T1 set column_name_1 = (select column_name_2 from table_name_2 T2 where T1.id = t2.id);
这种写法的错误之处在于,对于T1.id = t2.id,会从表2中的字段取出column_name_2来更新表1中的column_name_1的,而对于表1中的id不在表2中的,则会被设置为null。这样的风险是很高的。那么,如何避免这种情形呢?正确的写法是什么呢?
update table_name_1 T1 set column_name_1 = (select column_name_2 from table_name_2 T2 where T1.id = t2.id) where exists (select 1 from table_name_2 T2 where T1.id = T2.id);
增加了一句话, where exists (select 1 from table_name_2 T2 where T1.id = T2.id), 这样的结果就是,当T1中的id存在在T2中时,则进行更新,否则,不会进行更新。
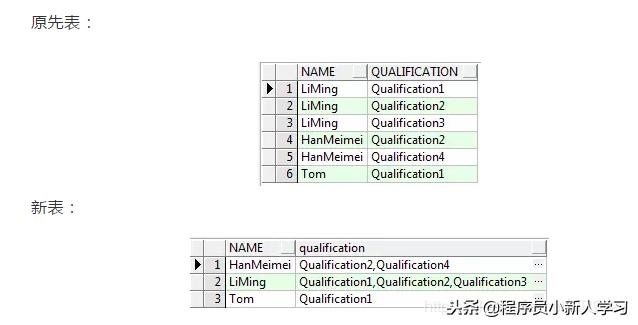
2、Oracle中的列转行
在表的设计中,通常会遇到这样的场景:某一行代表一个权限,比如用户A拥有权限A,B,C总共用三行数据。在统计的过程中,我们想查看用户A究竟总共有哪些权限呢?这就用到了Oracle中的列转行。
用法如下:
LISTAGG(column_name,',') WITHIN GROUP( ORDER BY column_name)
可以通过如下例子来理解:
with A as (select 'LiMing' name, 'Qualification1' qualification from dual union all select 'LiMing' name, 'Qualification2' qualification from dual union all select 'LiMing' name, 'Qualification3' qualification from dual union all select 'HanMeimei' name, 'Qualification2' qualification from dual union all select 'HanMeimei' name, 'Qualification4' qualification from dual union all select 'Tom' name, 'Qualification1' qualification from dual) select name, listagg(qualification, ',') within GROUP(order by qualification) as "qualification" from A group by name
3、 WITH AS 用法
有的时候,我们需要涉及到多表关联查询,然后将查询的结果进行汇总。那么,这种场景下,with as语法就非常有用。
with table_name_1 as (select .. ..), table_name_2 as (select .. ..), table_name_3 as (select .. ..) select .. . from table_name_1, table_name_2, table_name_3
这样写最大的好处是逻辑特别清晰,要查的数据不会因为多表关联或者join使得逻辑不清晰出现BUG。另外一大好处就是一次查询,多次使用。将查询结果放在临时表里面,后续可以对此表多次分析使用。
4、左连接LEFT JOIN
LEFT JOIN 关键字会从左表 (table_name_1) 那里返回所有的行,即使在右表 (table_name_2) 中没有匹配的行。此种场景下,如果采用多表关联查询,可能会丢失没有匹配的数据,所以,这种情况要采用左连接。
具体语法如下:
SELECT * FROM table_name_1 LEFT JOIN table_name_2 ON table_name_1.column_name = table_name_2.column_name
索引简介
索引是对数据库表中一个或多个列(例如,employee 表的姓名 (name) 列)的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引插叙的速度要比没有索引的速度要快很多。
MySQL中常见索引有:
- 普通索引
- 唯一索引
- 主键索引
- 组合索引
下面就应用一下索引吧
索引操作
一、普通索引(index)
普通所以只有一个功能,就是加快查找速度。操作如下:
1、先创建一个表
create table tab1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) )
2、创建索引
create index 索引名称 on 表名(列名)
3、删除索引
drop 索引名称 on 表名;
4、查看索引
show index from 表名;
5、注意事项(对于创建索引时如果是BLOB 和 TEXT 类型,必须指定length)
create index index_name on tab1(extra(32));
二、唯一索引(unique)
唯一性索引unique index和一般索引normal index最大的差异就是在索引列上增加了一层唯一约束。添加唯一性索引的数据列可以为空,但是只要存在数据值,就必须是唯一的。
1、创建表+唯一索引
create table tab2( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, unique ix_name (name) ## 重点在这里 )
2、创建索引
create unique index 索引名 on 表名(列名)
3、删除索引
drop unique index 索引名 on 表名
三、主键索引
在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。数据不能为空。
1、创建表+主键索引
create table in1( nid int not null auto_increment, name varchar(32) not null, email varchar(64) not null, extra text, primary key(nid), index zhang (name) )
2、创建主键
alter table 表名 add primary key(列名);
3、删除主键
alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key;
四、组合索引
组合索引,就是组合查询的意思嘛嘻嘻,将两列或者多列组合成一个索引进行查询。
其应用场景为:频繁的同时使用n列来进行查询,如:where name = '张岩林' and email = 666。
1、创建表
create table in3( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text )
2、创建组合索引
create index ix_name_email on in3(name,email);
如上创建组合索引之后,查询有的会使用索引,有的不会:
- name and email -- 使用索引
- name -- 使用索引
- email -- 不使用索引
索引注意事项
一、正确使用索引
数据库表中添加索引后能够让查询数据库速度飞快,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。
下面这些情况不会使用到索引:
1、like '%xx'
select * from tb1 where name like '%cn';
2、使用函数
select * from tb1 where reverse(name) = '张岩林';
3、or
select * from tb1 where nid = 1 or email='zhangyanlin@live.com'; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = 'zhangyanlin'; select * from tb1 where nid = 1 or email = 'zhangyanlin@live.com' and name = 'aylin'
4、类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where name = 999;
5、!=
select * from tb1 where name != 'aylin' 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123
6、>
select * from tb1 where name > 'alex' 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123
7、order by
select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc;
8、组合索引最左前缀
如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
二、其它注意事项
- 避免使用select *
- count(1)或count(列) 代替 count(*)
- 创建表时尽量时 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(经常使用多个条件查询时)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致
- 索引散列值(重复少)不适合建索引,例:性别不适合
三、执行计划
Explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化:
mysql> explain select * from tb2; +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | 1 | SIMPLE | tb2 | ALL | NULL | NULL | NULL | NULL | 2 | NULL | +----+-------------+-------+------+---------------+------+---------+------+------+-------+ 1 row in set (0.00 sec)
详细介绍如下:
id 查询顺序标识 如:mysql> explain select * from (select nid,name from tb1 where nid +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ | 1 | PRIMARY || ALL | NULL | NULL | NULL | NULL | 9 | NULL | | 2 | DERIVED | tb1 | range | PRIMARY | PRIMARY | 8 | NULL | 9 | Using where | +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ 特别的:如果使用union连接气值可能为null select_type 查询类型 SIMPLE 简单查询 PRIMARY 最外层查询 SUBQUERY 映射为子查询 DERIVED 子查询 UNION 联合 UNION RESULT 使用联合的结果 ... table 正在访问的表名 type 查询时的访问方式,性能:all ALL 全表扫描,对于数据表从头到尾找一遍 select * from tb1; 特别的:如果有limit限制,则找到之后就不在继续向下扫描 select * from tb1 where email = 'seven@live.com' select * from tb1 where email = 'seven@live.com' limit 1; 虽然上述两个语句都会进行全表扫描,第二句使用了limit,则找到一个后就不再继续扫描。 INDEX 全索引扫描,对索引从头到尾找一遍 select nid from tb1; RANGE 对索引列进行范围查找 select * from tb1 where name PS: between and in > >= 注意:!= 和 > 符号 INDEX_MERGE 合并索引,使用多个单列索引搜索 select * from tb1 where name = 'alex' or nid in (11,22,33); REF 根据索引查找一个或多个值 select * from tb1 where name = 'seven'; EQ_REF 连接时使用primary key 或 unique类型 select tb2.nid,tb1.name from tb2 left join tb1 on tb2.nid = tb1.nid; CONST 常量 表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。 select nid from tb1 where nid = 2 ; SYSTEM 系统 表仅有一行(=系统表)。这是const联接类型的一个特例。 select * from (select nid from tb1 where nid = 1) as A; possible_keys 可能使用的索引 key 真实使用的 key_len MySQL中使用索引字节长度 rows mysql估计为了找到所需的行而要读取的行数 ------ 只是预估值 extra 该列包含MySQL解决查询的详细信息 “Using index” 此值表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index访问类型弄混了。 “Using where” 这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引。 “Using temporary” 这意味着mysql在对查询结果排序时会使用一个临时表。 “Using filesort” 这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。 “Range checked for each record(index map: N)” 这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的。
四、limit分页
分页功能是个值得关注的问题,因为我们会一直用到:
每页显示10条: 倒序: 大 小 980 970 960 下一页: select * from tb1 where nid order by nid desc limit 10; select * from tb1 where nid order by nid desc limit 10; 上一页: select * from tb1 where nid 当前页最大值 order by nid asc limit 每页数据 *【当前页-页码】) A order by A.nid asc limit 1) order by nid desc limit 10; select * from tb1 where nid 980 order by nid asc limit 20) A order by A.nid desc limit 1) order by nid desc limit 10;
关键字: